本稿では、API Gatewayをプロキシサーバとして活用し、プライベートネットワークからパブリックネットワークへ接続する方法をご紹介します。一般的にはNAT Gatewayを利用する構成が多いですが、セキュリティ要件などによりインターネットへのアクセスを厳格に管理する必要がある場合、API Gatewayの活用が有効です。また、最近ではLLMが注目される中、API Gatewayの利用クオータが引き上げられました。今後このような活用事例も増えてくるかもしれません。
aws.amazon.com
また、先日投稿した記事もLLMのサービングに関連する記事です。
www.case-k.jp
本記事では詳細な説明は省略いたしますが、Terraformによる定義例を共有いたします。同様の活用事例を検討される方の参考になれば幸いです。
Terraform
ネットワークリソース
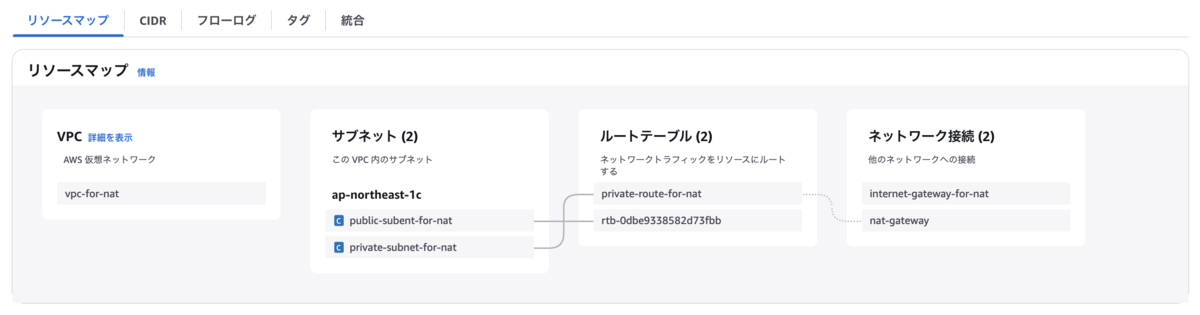
まず、ネットワークリソースについて簡単に説明いたします。今回扱うVPCのリソースマップは以下の通りです。
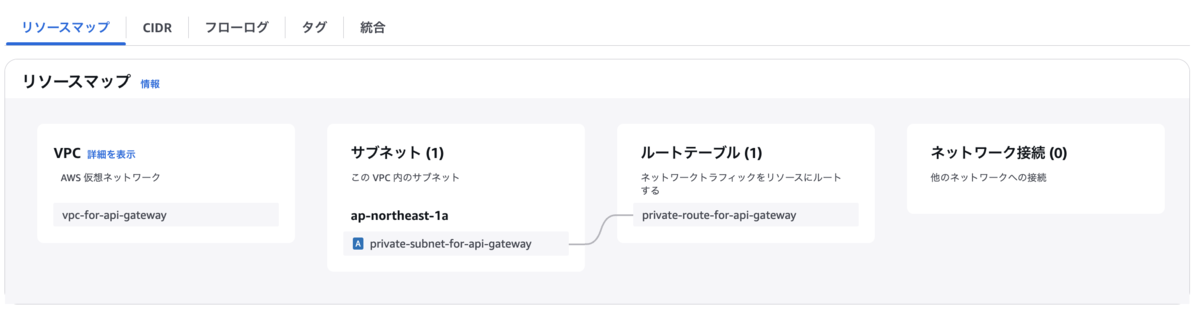
図から、ネットワーク接続にインターネットゲートウェイやNAT Gatewayが存在しないことが確認できます。
これは、API Gatewayをプロキシサーバとしてインターナルアクセスする場合、これらのリソースを自前で用意する必要がないためです。
なお、参考までに、NAT Gatewayを用いた構成例は以下のようになります。
まずはネットワークリソースの作成から始めます。VPC環境からAPI Gatewayへのインターナルアクセスを実現するため、VPCエンドポイントを活用します。
resource "aws_vpc" "vpc" { cidr_block = "10.0.0.0/16" enable_dns_support = true enable_dns_hostnames = true tags = { "Name" = "vpc-for-api-gateway" } tags_all = { "Name" = "vpc-for-api-gateway" } } # resource "aws_subnet" "aws_subnet_private" { resource "aws_subnet" "subnet_private" { vpc_id = aws_vpc.vpc.id cidr_block = "10.0.1.0/24" tags = { "Name" = "private-subnet-for-api-gateway" } tags_all = { "Name" = "private-subnet-for-api-gateway" } }
ingressにはself = trueを設定し、同じセキュリティグループ内のリソース同士で通信できるようになります。NAT Gateway には不要ですが、API Gateway の VPC エンドポイントアクセスなど、セキュリティグループ内のリソース間で HTTPS 通信が必要な場合に有用です。アウトバウンドのトラフィックは全て許可します。
resource "aws_security_group" "security_group" { vpc_id = aws_vpc.vpc.id # ingress does not need for nat gateway but need for API gateway VPC endpoint access ingress { from_port = 443 to_port = 443 protocol = "tcp" self = true } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { "Name" = "sg-private-subnet-for-api-gateway" } tags_all = { "Name" = "sg-private-subnet-for-api-gateway" } }
以下のコードは、Terraform を利用してプライベート API Gateway 用のルートテーブルおよび VPC エンドポイントを構築する例です。インターフェース型エンドポイントは、AWS PrivateLink を利用してプライベートにサービスに接続するためのものです。API Gatewayへのインターナル接続で利用します。
resource "aws_route_table" "private-route" { propagating_vgws = [] tags = { Name = "private-route-for-api-gateway" } tags_all = { Name = "private-route-for-api-gateway" } vpc_id = aws_vpc.vpc.id } resource "aws_route_table_association" "route_table_association" { subnet_id = aws_subnet.subnet_private.id route_table_id = aws_route_table.private-route.id } # ref # https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/apigateway-private-api-create.html resource "aws_vpc_endpoint" "vpc_endpoint" { vpc_id = aws_vpc.vpc.id service_name = "com.amazonaws.ap-northeast-1.execute-api" vpc_endpoint_type = "Interface" subnet_ids = [ aws_subnet.subnet_private.id ] security_group_ids = [ aws_security_group.security_group.id, ] private_dns_enabled = true tags = { Name = "vpc-endpoint-for-api-gateway" } tags_all = { Name = "vpc-endpoint-for-api-gateway" } }
API Gateway
以下はAPI Gatewayの定義例です。詳細は省略いたしますが、API Gatewayをプロキシサーバとして活用する構成となっています。APIエンドポイントのタイプはプライベートに設定し、VPCエンドポイントから接続できるようにしています。デプロイ後、API Gatewayのエンドポイントにリクエストを送ると、指定したエンドポイントへアクセスが可能です。

REST API の基本情報(名前やAPIキーの受け取り方法など)を設定し、リソースポリシーで「aws:SourceVpc」が指定の VPC と一致する場合のみ呼び出しを許可する条件を付与しています。また、エンドポイントを PRIVATE に設定し、特定の VPC エンドポイント(aws_vpc_endpoint.vpc_endpoint.id)と連携させています。
resource "aws_api_gateway_rest_api" "api_gateway_rest_api" { api_key_source = "HEADER" binary_media_types = [] body = null description = null disable_execute_api_endpoint = false fail_on_warnings = null minimum_compression_size = null name = "api-private-gw" parameters = null # policy = null policy = jsonencode({ Version = "2012-10-17" Statement = [ { Effect = "Allow" Principal = "*" Action = "execute-api:Invoke" Resource = "execute-api:/*" # Resource = "arn:aws:execute-api:ap-northeast-1:132483466678:l9jk54cpy0/*" Condition = { StringEquals = { "aws:SourceVpc" = aws_vpc.vpc.id } } } ] }) put_rest_api_mode = "overwrite" tags = {} tags_all = {} endpoint_configuration { types = ["PRIVATE"] vpc_endpoint_ids = [aws_vpc_endpoint.vpc_endpoint.id] } }
API のルートリソース直下に、パスパラメータ "{proxy+}" を持つリソースを作成します。
resource "aws_api_gateway_resource" "api_gateway_resource" { depends_on = [aws_api_gateway_rest_api.api_gateway_rest_api] # parent_id = aws_api_gateway_resource.api_gateway_resource_parent.id parent_id = aws_api_gateway_rest_api.api_gateway_rest_api.root_resource_id path_part = "{proxy+}" rest_api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id }
上記リソースに対して HTTP のすべてのメソッド(ANY)を許可し、APIキー認証を必須としています。リクエストパラメータとして URL のパス部分を必須に設定。
resource "aws_api_gateway_method" "api_gateway_method" { depends_on = [aws_api_gateway_resource.api_gateway_resource] api_key_required = true authorization = "NONE" authorization_scopes = [] authorizer_id = null http_method = "ANY" operation_name = null request_models = {} request_parameters = { "method.request.path.proxy" = true } request_validator_id = null resource_id = aws_api_gateway_resource.api_gateway_resource.id rest_api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id }
メソッド呼び出し成功時(200)のレスポンスモデルを定義。
resource "aws_api_gateway_method_response" "api_gateway_method_response" { rest_api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id resource_id = aws_api_gateway_resource.api_gateway_resource.id http_method = aws_api_gateway_method.api_gateway_method.http_method status_code = "200" response_models = { "application/json" = "Empty" } }
バックエンドからのレスポンスを、JSON テンプレート(空のスキーマ)に変換する設定を行っています。
resource "aws_api_gateway_integration_response" "api_gateway_integration_response" { rest_api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id resource_id = aws_api_gateway_resource.api_gateway_resource.id http_method = aws_api_gateway_method.api_gateway_method.http_method status_code = aws_api_gateway_method_response.api_gateway_method_response.status_code response_templates = { "application/json" = jsonencode( { "$schema" = "http://json-schema.org/draft-04/schema#" title = "Empty Schema" type = "object" } ) } }
API の呼び出しに必要な API キー(ここでは "test-key")を作成。
resource "aws_api_gateway_api_key" "api_gateway_api_key" { customer_id = null description = null enabled = true name = "test-key" tags = {} tags_all = {} value = null # sensitive }
1日あたりのリクエスト上限(クォータ)やスロットリング(バースト・レート制限)を設定し、対象の API ステージ("test")を紐付けています。
resource "aws_api_gateway_deployment" "api_gateway_deployment" { depends_on = [aws_api_gateway_method.api_gateway_method] description = null rest_api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id stage_description = null stage_name = null triggers = null variables = null }
作成した API キーと使用量プランを関連付け、API キー利用者に対して制限を適用します。
resource "aws_api_gateway_stage" "api_gateway_stage" { cache_cluster_enabled = false cache_cluster_size = null client_certificate_id = null deployment_id = aws_api_gateway_deployment.api_gateway_deployment.id description = null documentation_version = null rest_api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id stage_name = "test" tags = {} tags_all = {} variables = {} xray_tracing_enabled = false } resource "aws_api_gateway_usage_plan" "api_gateway_usage_plan" { description = null name = "test-gw-plan" product_code = null tags = {} tags_all = {} api_stages { api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id stage = aws_api_gateway_stage.api_gateway_stage.stage_name } quota_settings { limit = 20 offset = 0 period = "DAY" } throttle_settings { burst_limit = 5 rate_limit = 5 } } resource "aws_api_gateway_usage_plan_key" "api_gateway_usage_plan_key" { key_id = aws_api_gateway_api_key.api_gateway_api_key.id key_type = "API_KEY" usage_plan_id = aws_api_gateway_usage_plan.api_gateway_usage_plan.id }
定義したメソッド(ANY)に対して、HTTP プロキシ統合を設定し、受け取ったリクエストを https://httpbin.org/get に転送します。キャッシュのキーとしてパスパラメータを利用し、タイムアウトなどの挙動も指定しています。
resource "aws_api_gateway_integration" "api_gateway_integration" { cache_key_parameters = ["method.request.path.proxy"] cache_namespace = aws_api_gateway_resource.api_gateway_resource.id connection_id = null connection_type = "INTERNET" content_handling = null credentials = null http_method = "ANY" integration_http_method = "GET" passthrough_behavior = "WHEN_NO_MATCH" request_parameters = { "integration.request.path.proxy" = "method.request.path.proxy" } request_templates = {} resource_id = aws_api_gateway_resource.api_gateway_resource.id rest_api_id = aws_api_gateway_rest_api.api_gateway_rest_api.id timeout_milliseconds = 5000 type = "HTTP" uri = "https://httpbin.org/get" }
Lambda
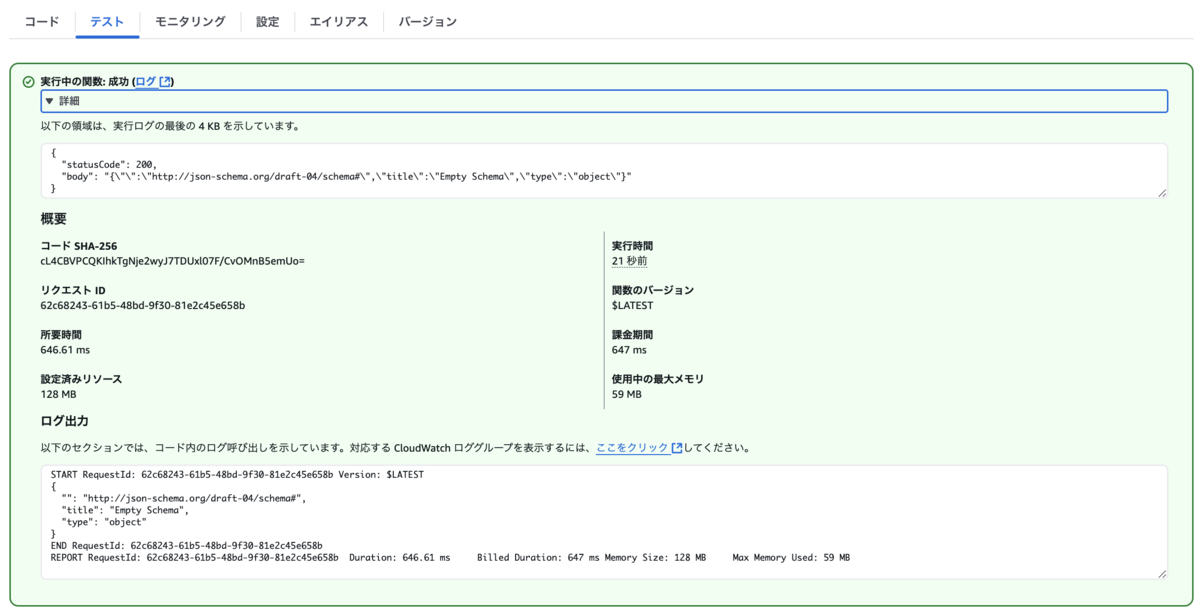
疎通確認用にLambdaをVPCにデプロイします。
import requests import json def lambda_handler(event, context): # ref # url = "https://httpbin.org/get" url = "https://<api-gw-id>.execute-api.ap-northeast-1.amazonaws.com/test/{proxy+}" # APIキーを指定 api_key = "api-key" headers = { "x-api-key": api_key } response = requests.get(url, headers=headers) print(response.text) return { "statusCode": response.status_code, "body": response.text }
Terraform
data "archive_file" "lambda_zip" { type = "zip" source_dir = "../app/lambda/python/package" output_path = "../app/lambda/python/lambda_function.zip" } resource "aws_lambda_function" "lambda_function_for_api_gateway" { depends_on = [data.archive_file.lambda_zip] function_name = "lambda_function_for_api_gateway" role = aws_iam_role.lambda_sample_function.arn handler = "lambda_function.lambda_handler" runtime = "python3.11" memory_size = 128 timeout = 5 source_code_hash = filebase64sha256(data.archive_file.lambda_zip.output_path) filename = data.archive_file.lambda_zip.output_path vpc_config { subnet_ids = [aws_subnet.subnet_private.id] security_group_ids = [aws_security_group.security_group.id] } }