Databricks Advent Calendar 2025 シリーズ2 25日目の記事です。Oracle を Databricks にマイグレーションする機会があり、LLM を用いた自動コンバージョンツールとコンバージョン結果を評価するための dbtの評価基盤を構築しました。本記事では、コンバージョン評価プロセス全体の流れとその開発・検証の過程で得られた技術的な Tips をご紹介します。LLMを用いたマイグレーション全般に適用できる内容として整理しているため、同じような悩みを持つ方の参考になれば幸いです。
コンバージョン評価プロセス全体の流れ
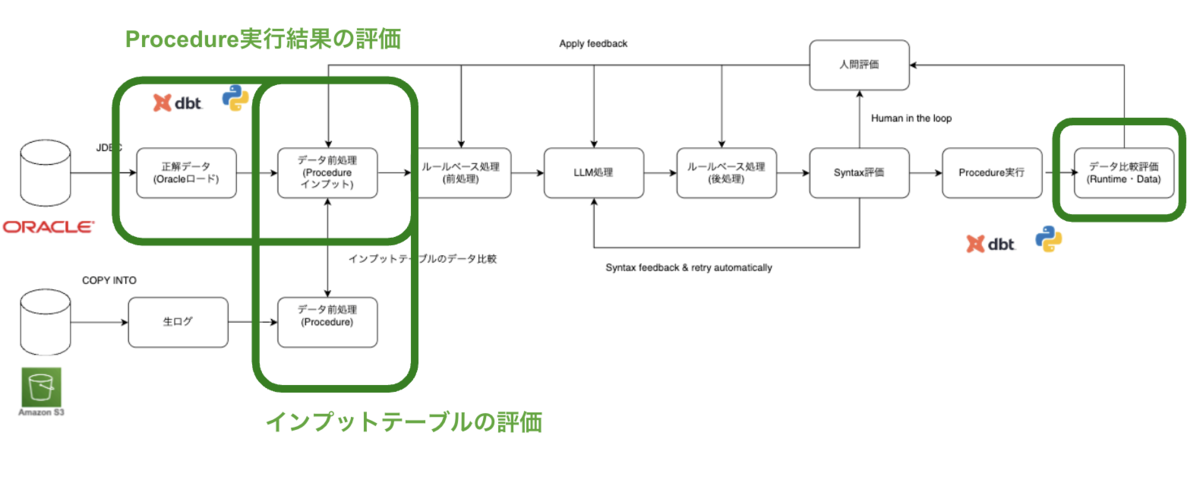
最初にコンバージョン評価プロセス全体の流れを紹介します。PL/SQL のコンバージョンには LLM ベースのコンバージョンツールを使用しています。また、コンバージョン結果をデータ比較し、評価する仕組みも必要です。評価基盤にはdbtを利用しています。LLMコンバージョンツールやdbt 評価基盤の詳細は次の章で説明し、まずは全体のプロセスの流れを説明します。
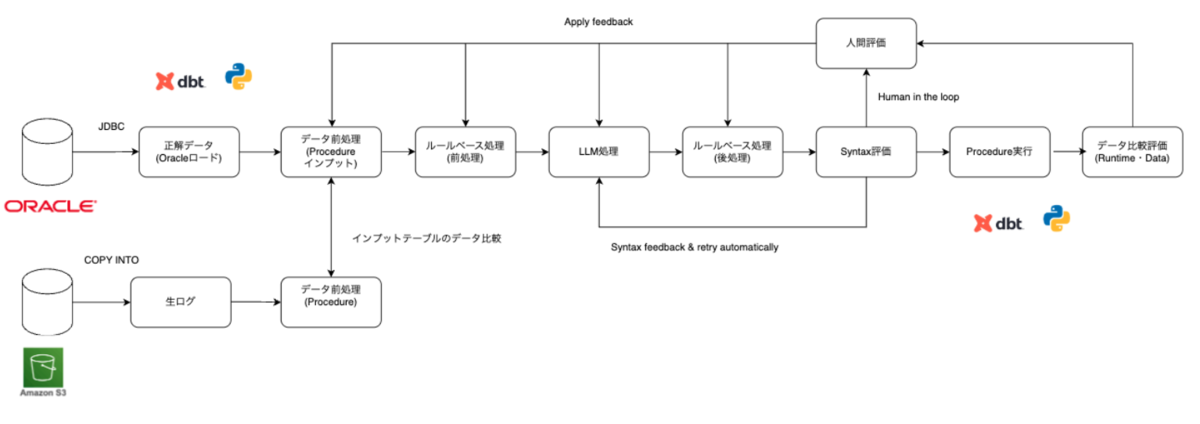
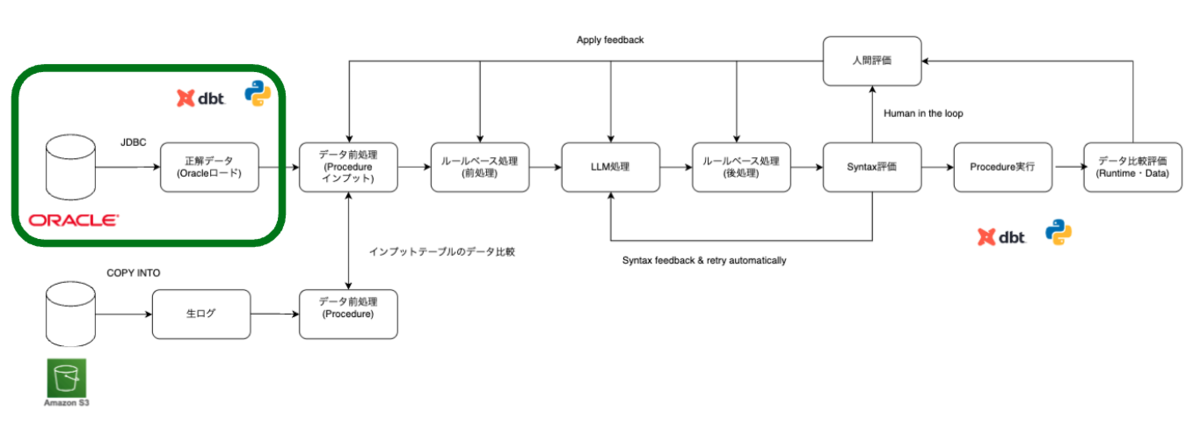
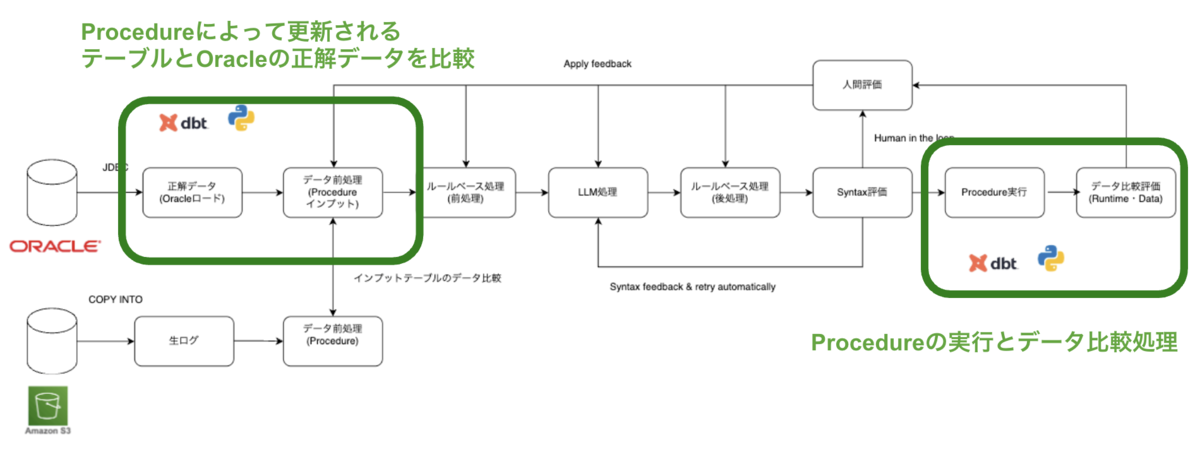
データ評価を行うためには、正解データを用意する必要があります。そこで、既存の Oracle 環境において日次で実行されている Procedure バッチ処理完了後のテーブルを、Databricks にロードしています。ロードしたテーブルには日付ごとにサフィックスを付与し、カタログを分けて管理しています(例:prod_oracle_20251225)。日付ごとに断面を分けている理由は、静的なデータ断面を用いることで、複数のデータ評価者がそれぞれ割り当てられた日付断面を使用し、互いに影響を受けることなく、独立した環境でデータ評価を行えるようにするためです。また、この後紹介するProcedureのデータ比較評価に必要な環境を作るためにも利用されます。
ロードされたOracleのデータを用いて、Procedureのデータ比較評価に必要な環境(以降、評価環境と呼びます)を構築します。
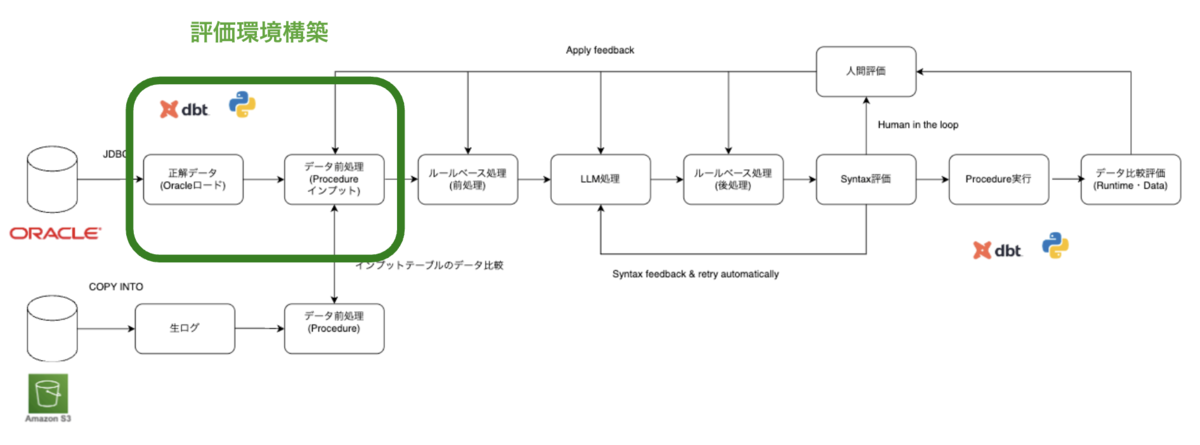
評価環境で使用するデータは、次の 2 種類です。
1 つ目は、日次で連携され、Procedure のインプットとなるテーブルです(以降「インプットテーブル」と呼びます)。
2 つ目は、インプットテーブル以外で、Procedure の実行によって更新されるテーブルです。
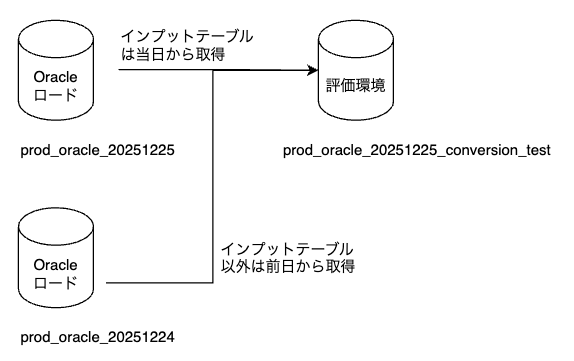
評価者はそれぞれデータ比較する対象日をdbt の設定ファイル内で指定して評価を行います。インプットテーブルには、指定された日付断面の Oracle テーブルを使用し、それ以外のテーブルについては、指定日付の前日断面の Oracle テーブルを利用します。このように構成することで、Procedure 実行後の評価環境は、テーブルが更新され、Oracle におけるバッチ処理完了後の状態と一致します。
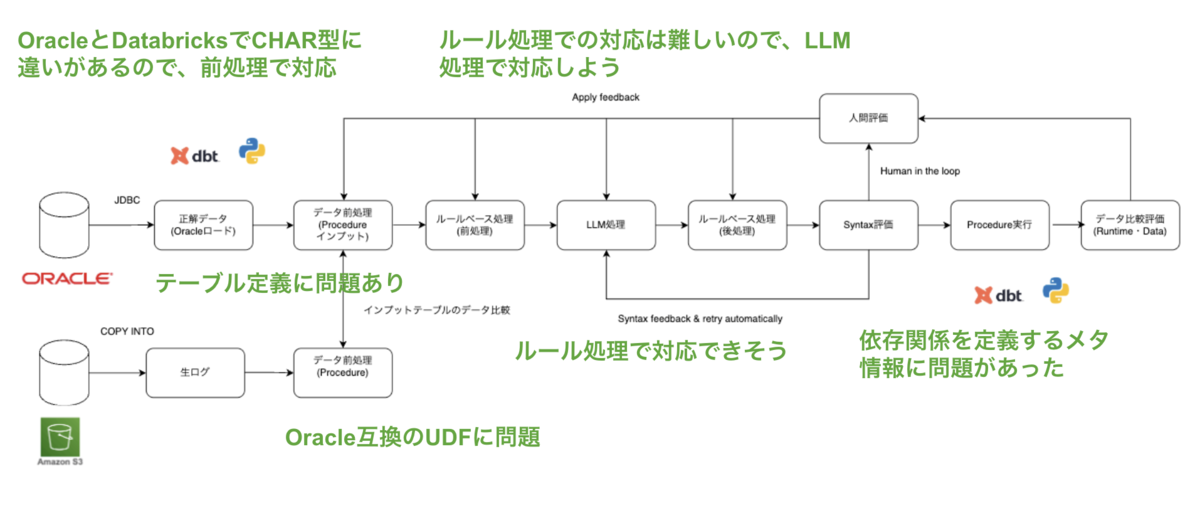
また、評価環境の構築時には、データレベルの前処理が必要です。Oracle と Databricks ではデータ型の挙動に差異があるためです(例:CHAR 型は Oracle ではCHARサイズに応じてスペース埋めされますが、Databricks ではされません)。こうした差異は、 Procedure のデータ比較評価結果をもとに、前処理として吸収しています。次にLLMコンバージョンツールを使い、Oracle PL/SQLをDatabricks Procedureにコンバージョンします。Databricks Procedureについては以下に詳細を書きました。
LLMコンバージョンツールでは正規表現等の「ルール処理」と「LLM処理」を組み合わせて自動コンバージョンしています。Databricks ProcedureはSQLウェアハウスで実行できるので、変換後にAPIを使い、「CREATE PROCEDURE」でUnity Catalogに登録します。Syntaxレベルのエラーがあった場合、「CREATE PROCEDURE」実行時に検知することができます。PySparkでのジョブ起動等ないため、改善サイクルを高速に回すことができました。Syntaxエラーとなった場合、エラーメッセージとコンバージョン結果をプロンプトに組み込み、リトライします。数回リトライしても改善しなかった場合、「人間」が確認し、LLMコンバージョンツールに修正等フィードバックします。Syntaxレベルのエラーが改善されるまで、繰り返します。
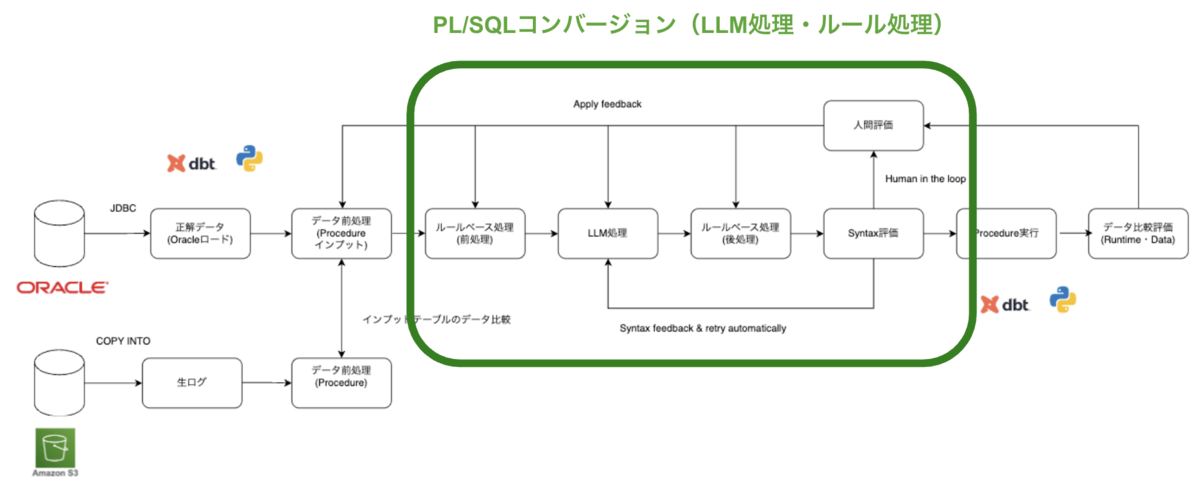
次にdbtを用いて、Procedureの実行とデータ比較評価を行います。dbt Pythonモデルを用いてProcedureを実行すると、先ほど紹介した評価環境のテーブルが更新されます。更新された結果はOracleからロードした当日断面と同じ結果になっているため、データ比較することで、差分の確認ができます。
データ比較の差分結果を「人間」が確認し、どのタスクにフィードバックするか判断し修正することで、改善サイクルを回します。データ評価のフィードバック先は多岐に渡ります。依存関係等のメタ情報の不備の場合もあれば、テーブル定義、データの前処理、LLMコンバージョンツール、コンバージョン結果、UDF等考えられます。データの差分結果を考慮して、適切なタスクにフィードバックして、改善します。
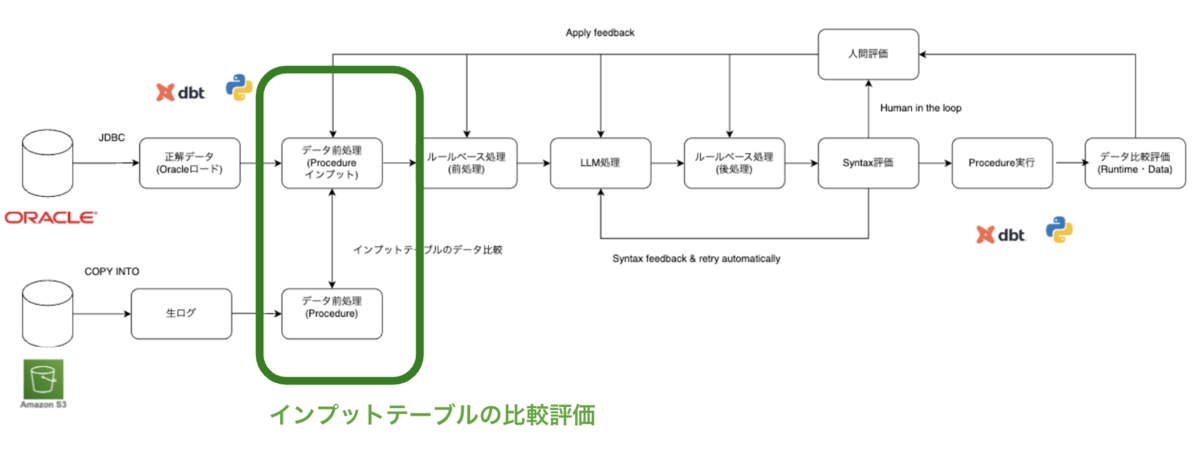
Procedure の評価が完了した後は、日次で連携されてくるProcedureのインプットテーブルの評価を行います。インプットテーブルはオブジェクトストレージ(S3等)経由で連携を想定します。連携時にはまだProcedureのフィードバックを反映したインプットテーブルになっていないため、前処理を行い、評価環境のインプットテーブルと一致するようにデータ比較します。
全体の評価フローは、まず Procedure 単体テストから始めます。次に Procedure 同士の依存関係を考慮した結合テストを行い、その後、Procedureのテスト結果が反映された評価環境を正解データとし、インプットテーブルの単体テストをします。最後に、インプットテーブルと Procedure を組み合わせた結合テストを行います。一連の評価が完了した後は、日次バッチとして実行し、継続的に監視します。並行稼働期間中は、データの差分や不整合を継続的に検知できるようになります。
以上が、コンバージョン評価プロセス全体の流れです。次章からは具体的なLLMコンバージョンツールとdbt評価基盤の技術的なTipsをご紹介していきます。
LLMコンバージョンツール
LLMコンバージョンツールで行っていることの詳細をご紹介します。
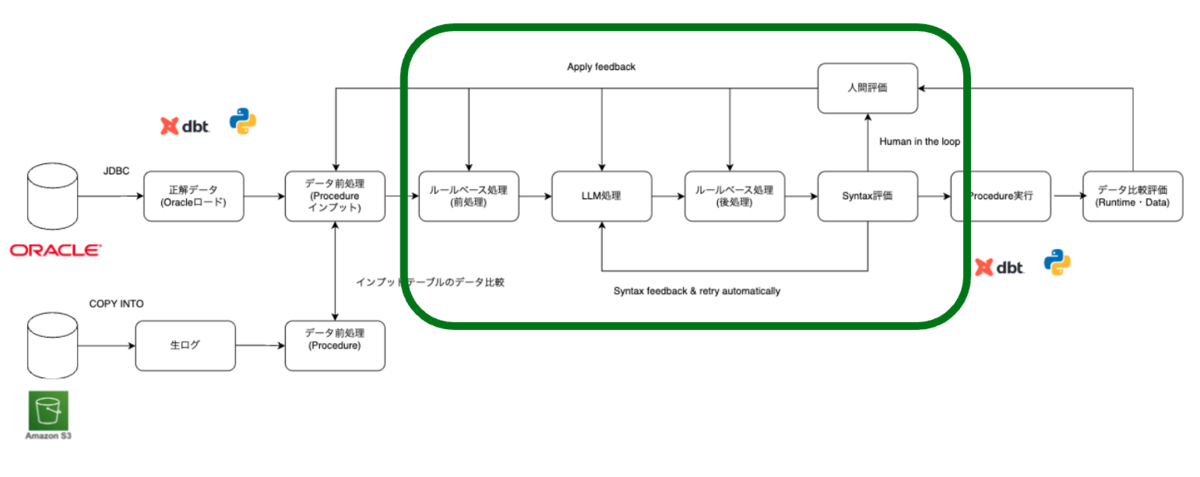
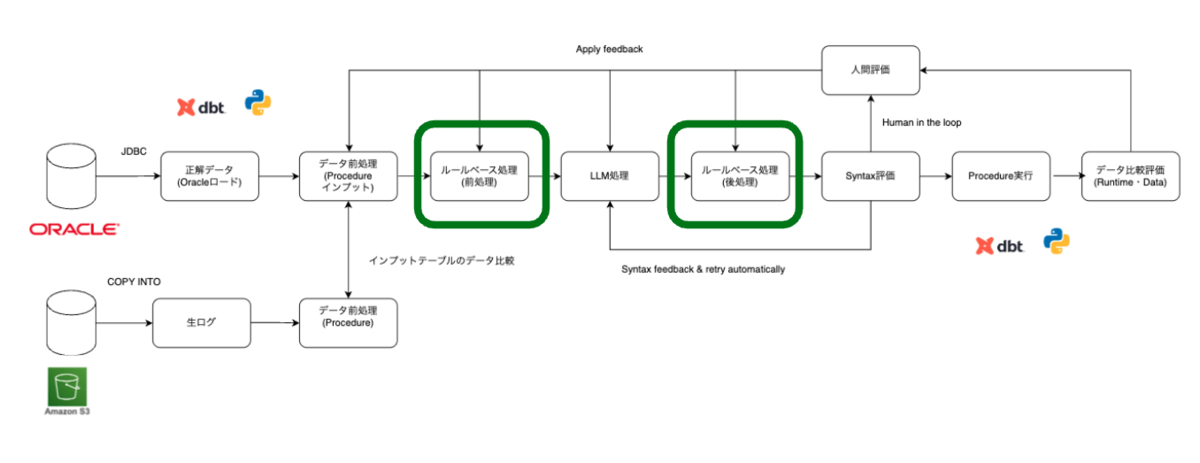
ルール処理(前処理・後処理)
LLM は非決定的であり、コンテキストウィンドウや出力トークンにも制限があります。そのため、正規表現などで対応可能な部分についてはルールベース処理を採用し、正規表現では対応が難しい箇所のみ LLM を利用しています。ルールベースで対応可能な部分はルール処理に任せることで、変換精度と安定性を高めています。
コメント削除等によるコンテキスト削減
前処理では、 PL/SQL に含まれるコメントや不要な改行を削除し、LLM に渡す前のコンテキスト量を削減しています。これにより、コンテキスト量をおおよそ 1/3 程度削減することができました。空白等も当初は削除していましたが、Procedureのデータ比較を通して、削除してはいけないことがわかったので、対象から外しています「normalize_whitespace: false」。
input_preprocessing: remove_comments: true # Remove all SQL comments (-- and /* */) from input remove_empty_lines: true # Remove empty lines from input normalize_whitespace: false # Normalize multiple spaces/tabs to single space compress_sql_formatting: true # Remove line breaks within SQL statements for compact formatting
正規表現での変換
正規表現で変換可能な箇所については、すべて正規表現による「ルール処理」で対応しました。具体的には、日付フォーマットの変換や日本語変数をバッククオートで囲む処理、Oracle 互換の関数変換などを正規表現で変換しました。LLM は変換結果が不安定になるケースもあるため、正規表現で対応できる部分については、ルールベース処理の方がより正確かつ安定した変換が可能です。
- (例)日本語を含む変数に対するバッククオートの付与
日本語を含む変数名に対するバッククオートの付与は、LLM では特に変換漏れが発生しやすいポイントでした。英語と日本語が混在するケースでは、LLM がカラムを見落とすことが多く、安定した変換が困難でした。
INSERT INTO `TEMP_利用者`( ID, `名前` ) SELECT USER.ID USER.`ユーザー` FROM USER
- (例)日付フォーマット変換
PL/SQL と Databricks では日付フォーマットの指定方法に差異があるため、これらは正規表現によるルール処理で変換しています。
YYYYMMDD → yyyyMMdd yyyy/mm/dd → yyyy/MM/dd YYYY/MM/DD → yyyy/MM/dd YYYY/mm/dd → yyyy/MM/dd
- (例)Oracle 互換関数の変換
Oracle 互換の関数については、Databricks 側に互換 UDF を用意して利用しています。関数の変換等はLLMよりもルールベースの方が正確かつ、LLMで消費するコンテキスト量も減らすことができます。
function_mappings: TO_DATE: "oracle_compatible.TO_DATE" # TO_DATE(str, fmt) → oracle_compatible.TO_DATE(str, fmt) TO_CHAR: "oracle_compatible.TO_CHAR" # TO_CHAR(value, fmt) → oracle_compatible.TO_CHAR(value, fmt) ADD_MONTHS: "add_months" # ADD_MONTHS(date, n) → add_months(date, n) NVL: "coalesce" # NVL(expr1, expr2) → coalesce(expr1, expr2) TRIM: "oracle_compatible.TRIM" # TRIM(col) → oracle_compatible.TRIM(col) RTRIM: "oracle_compatible.RTRIM" # RTRIM(col) → oracle_compatible.RTRIM(col) LTRIM: "oracle_compatible.LTRIM" # LTRIM(col) → oracle_compatible.LTRIM(col) SUBSTRB: "SUBSTR" SYSTIMESTAMP: "current_timestamp()" # SYSTIMESTAMP → current_timestamp() SYSDATE: "current_timestamp()" # SYSDATE → current_timestamp() TO_NUMBER: "oracle_compatible.TO_NUMBER" # TO_NUMBER(col) → oracle_compatible.TO_NUMBER(col) TRUNC: "FLOOR" # TRUNC(number, scale) → FLOOR(number, scale) current_date: "current_timestamp()" ....
LLM処理
ルール処理だけでは対応が難しい部分は「LLM処理」で対応しています。行数の多いPL/SQLをコンバージョンするための工夫やLLMの不安定さを取り除くための方法を紹介します。
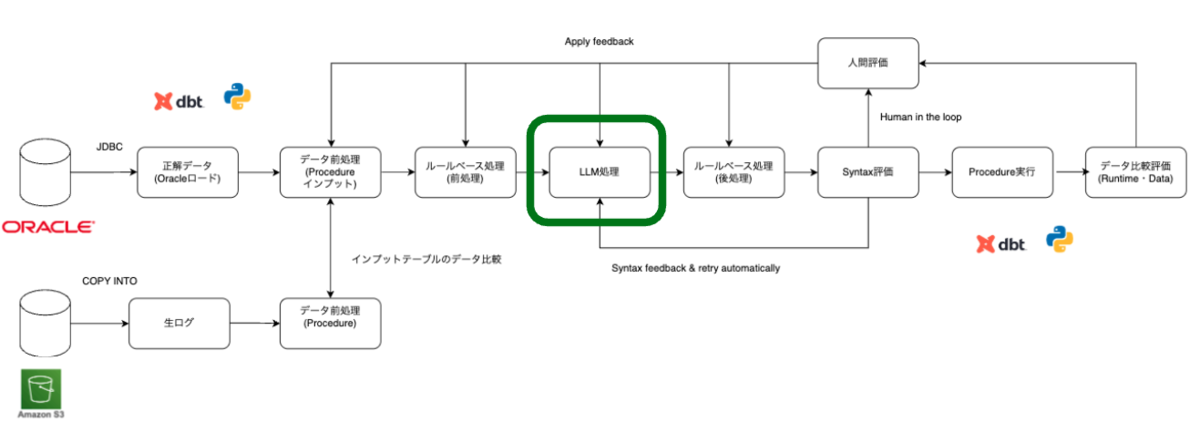
数千行以上のPL/SQL をコンバージョンする方法:会話履歴・出力の分割と結合・リクエストパラメータ制御
数千行を超えるような行数の多い PL/SQL は、前処理によってコンテキスト量を削減しても、モデルの出力トークン制限を回避することは難しいです。
例えば Claude 3.7 Sonnet では、コンテキストウィンドウ(200,000トークン)および出力トークン(64,000トークン)に上限があり、そのままリクエストすると出力トークン制限に達してしまいます。また、モデルの許容するコンテキスト上限ギリギリでリクエストした場合、出力の一部が途中で欠落することも確認できました。
そこで、リクエスト時に余裕を持った出力トークン 「max_output_tokens 」を設定し、出力トークンの上限に達した場合は、途中までの変換結果を会話履歴として保持し、続きから再生成する仕組みを実装しました。この方法により、ベンダーが提供するモデルの出力トークン制限を回避しています。
具体的には、以下の流れで処理を行っています。
conversion_settings: default_temperature: 0.0 default_max_tokens: 60000 # Set max_output_tokens with a sufficient margin. default_stream: true # Enable streaming output by default
出力トークンの上限に達した場合は、生成済みの結果を会話履歴として保存します。finish_reason が「length」の場合、次の LLM リクエストではその履歴をプロンプトとあわせて渡し、前回の続きからコードを再生成します。この処理を繰り返し、分割生成された結果を CONCAT して統合することで、行数の多い Procedure の変換を行っています。
# Continue if truncated due to length limit while final_finish_reason == 'length' and continuation_count < max_continuations: continuation_count += 1 print(f"{context_prefix}Response truncated, requesting continuation {continuation_count}/{max_continuations}...") # Add continuation request to conversation history current_messages.append({"role": "user", "content": continuation_prompt or "Please continue from where you left off. Provide only the continuation without repeating what's already provided."}) try: if stream: # Use streaming version for continuation continuation_content, finish_reason, cont_token_usage = self._single_stream_request_with_metadata( current_messages, temperature, max_tokens, context_prefix ) except Exception as e: ...... full_text += continuation_content current_messages.append({"role": "assistant", "content": continuation_content}) final_finish_reason = finish_reason
PL/SQL のコンバージョンでは正確性と一貫性が重要となるため、「temperature」は低めに設定し、出力の揺らぎを抑えています。また、行数の多いファイルでは タイムアウトが発生するするため、「stream」オプションを利用してストリーミングで結果を受け取ることで回避できます。さらに、出力トークンは意図的に小さく設定し、上限に達した場合は会話履歴を用いた分割生成を行うことで、出力トークン制限に対応しています。出力トークンを意図的に小さく設定しないと、LLM側で勝手に出力結果を削ったり、サマライズしたりしてしまうので、注意が必要です。
以下のサンプルはOpenAI Client を使用し、ストリーム処理で、Databricksのモデルサービングを利用する例です。
Use foundation models | Databricks on AWS
def chat_completion_stream(self, messages: List[Dict[str, str]], temperature: Optional[float] = None, max_tokens: Optional[int] = None) -> Iterator[Dict[str, Any]]: """Send streaming chat completion request to Databricks Model using OpenAI SDK""" params = { 'model': self.model_id, 'messages': messages, 'temperature': temperature } if max_tokens is not None: params['max_tokens'] = max_tokens # Use OpenAI SDK for streaming (following working sample.py approach) with self.openai_client.chat.completions.stream(**params) as stream: for event in stream: if event.type == "chunk": print(f'raw chunk finish_reason: {event.chunk.choices[0].finish_reason}') finish_reason = event.chunk.choices[0].finish_reason if event.type == "content.delta": # event.delta is the text fragment (plain string) chunk_text = event.delta print("content.delta") print(event) # Create OpenAI-compatible chunk format chunk = { 'choices': [{ 'delta': { 'content': chunk_text }, 'index': 0 }] } yield chunk elif event.type == "error": # Return error in expected format yield {"error": event.error} break elif event.type == "content.done": # Debug: check event attributes print(f"🔍 content.done event: {event}") # Send final chunk with actual finish_reason final_chunk = { 'choices': [{ 'delta': {}, 'index': 0, 'finish_reason': finish_reason }] } yield final_chunk break
このようにして、LLM モデルの出力トークン制限を回避しつつ、コンテキストウィンドウの上限近くまで対応できるようになります。
ただし、この処理をしてもコンテキストウィンドウの制限を回避することはできないので、数万行レベルのPL/SQLは事前に分割しておく必要があります。また、5,000 行を超える PL/SQLでは変換精度が低下する傾向があるため(コンテキストロット問題:入力トークン量(会話履歴)増加に伴う能力低下現象)、一定の行数を超える場合は、前処理として PL/SQL自体を事前に分割した方が良さそうです。会話履歴を活用した分割変換は、精度を維持したまま制限を回避できる有効な手法でした。一方で、履歴情報の渡し方ではコンテキスト圧縮なども試しましたが、十分な効果は得られませんでした。PL/SQL のコメントはできれば残したいと思いますが、精度とトレードオフとなってくるので、コンテキストウィンドウの制限がある現時点ではバランスを見て判断した方がいいと思います。
プロンプトの継続的改善とバージョン管理
PL/SQL を Databricks Procedure に変換するにあたり、LLM が十分な知識を持っていなかったため、公式ドキュメントやベンダー側のベストプラクティスをもとにベースプロンプトを作成しました。ただし、ドキュメントに記載のない仕様も多くあるため、データ評価結果をプロンプトにフィードバックし、継続的に改善しました。当初は関数変換も LLM に任せていましたが、不安定さや変換漏れが多く、また評価結果を反映しすぎるとコンテキスト肥大によるデグレも発生しました。そのため最終的には、「ルール処理」で対応できない部分のみに 「LLM 処理」を限定し、コンテキストを抑えることで精度と安定性を両立しています。また、LLMが十分な知識を持っていないため、「LLM処理」もしくは「ルール処理」どちらにも変換方法を明示していないものは不安定な出力となりました。コンバージョンでは変換結果の一貫性が重要となるため、基本的にはどちらかには変換方法を明示しています。
また、プロンプトのバージョン管理は GitHub のみで行っています。改善サイクルを高速に回すことを重視していたため、ローカル環境から実行でき、VS Code エディタ内で完結する形で GitHub 管理としました。デグレが発生した場合も、プロンプトファイルのコミットを戻すだけで対応できます。
Syntaxエラー自動リトライによる出力の安定化
PL/SQL コンバージョンの単体テストでは、Syntax・Runtime・データレベルの 3 段階で評価しています。このうち Syntax レベルの評価は、LLM コンバージョンツール内で、自動修正しています。Runtime・データレベルはデータ起因や他の要因も考えられるため、LLM コンバージョンツール内では対応していないです。
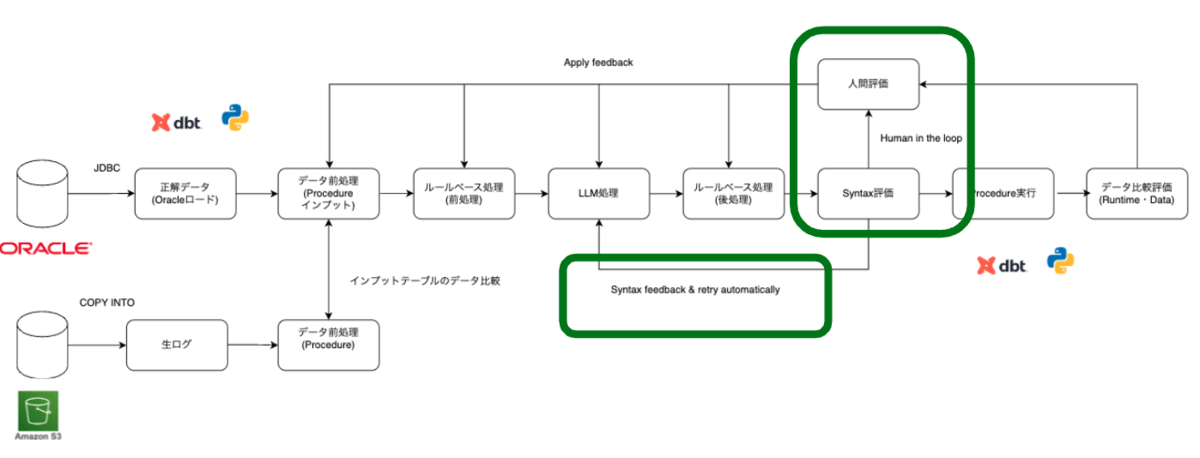
「コンバージョン評価プロセス全体の流れ」で紹介した通り、コンバージョン結果をAPI 経由で SQL ウェアハウスに対して 「CREATE PROCEDURE」 を実行し、Syntax エラーがあれば即時検知されます。LLM の不安定さを考慮し、プロンプトにコンバージョン結果とSyntax エラーメッセージを加え、最大 3 回までリトライし、それでも解消しないものは「人間」が確認してツールにフィードバックしています。ツール内の「LLM処理」を改善するか、「ルール処理」を改善するかはエラー内容を見て判断しました。エラー内容やSyntaxエラーとなったコンバージョン結果はファイルに出力し、トレーシング可能な形で管理し、フィードバックの参考にしています。先ほどもお伝えしたとおり、改善サイクルを高速に回すため、ローカル環境で完結できることを重視していました。そのため、コンバージョン結果やSyntaxエラー内容をファイルとして出力し、トレーシングできる運用を取りました。
以下はSyntaxエラーリトライ時のサンプルとなります。プロンプトにコンバージョン結果とエラーメッセージを加えて、リトライしてるのが確認できます。
for attempt in range(1, max_retries + 1): print(f"{error_type} fix attempt {attempt}/{max_retries}") try: # Create fix prompt based on error type if error_type == "syntax_error": fix_prompt = f"""The following Databricks SQL has a syntax error. Please fix it. Error message: {current_error} SQL: {current_sql} Please return only the corrected SQL (no comments or explanations needed)."""
評価・改善はすべてローカル環境で高速に回し、全ProcedureのSyntaxレベルの改善は1週間程度で対応できました。Databricks Procedureがサポートされ、直接SQLウェアハウス実行できるようになったことも改善サイクルの高速化につながりました。
dbt 評価基盤
dbt 評価基盤で行っていることの詳細をご紹介します。
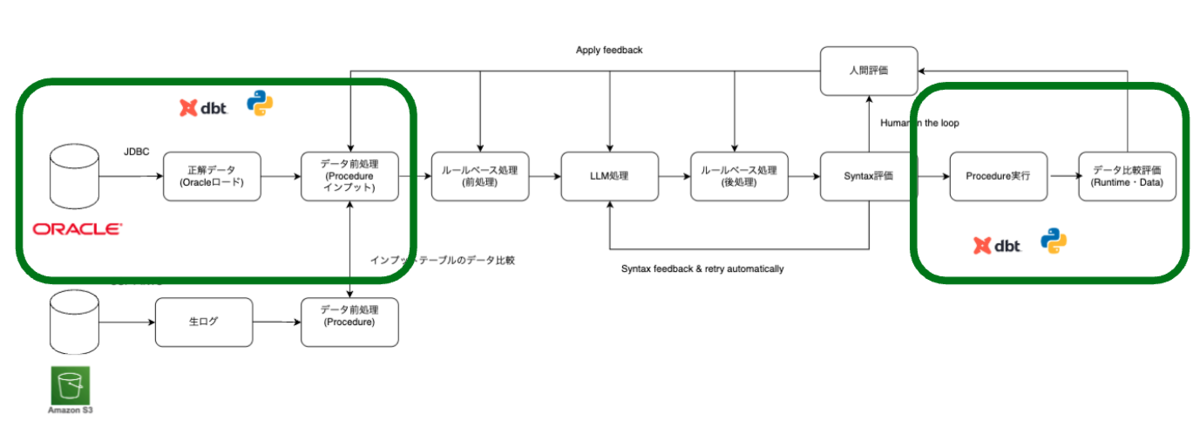
正解データの準備
「コンバージョン評価プロセス全体の流れ」で紹介した通り、日次で Oracle のテーブルを Databricks にロードしています。ロードには dbt Pythonモデルを利用しています。dbt Pythonモデルは Python で ETL ロジックを記述でき、Databricks の Notebook Job として実行可能です。SQL では難しい処理にも対応でき、SQLモデルとの依存関係も制御できます。dbtのエコシステムを利用できるので便利です。
Databricks configurations | dbt Developer Hub
Python models | dbt Developer Hub
以下のサンプルはdbt Pythonモデル内で、JDBCドライバを使い、Oracleのテーブルをロードするサンプルです。テーブル数が多い場合、テーブルごとにモデルを作成するとモデル数が膨大になってしまうので、マルチスレッド処理等で対応した方が良いと思います。Pythonが使えるので、柔軟な処理が可能です。
(例) Oracleに永続化されているテーブルをDatabricksへロード
import boto3 def model(dbt, session): dbt.config( materialized='table', tags=['sample'], ) host = dbt.config.get('dbx_host') ssm = boto3.client('ssm', region_name=dbt.config.get('region')) user = ssm.get_parameter(Name=dbt.config.get('jdbc_user_path'), WithDecryption=True)['Parameter']['Value'] pwd = ssm.get_parameter(Name=dbt.config.get('jdbc_password_path'), WithDecryption=True)['Parameter']['Value'] jdbc_url = ssm.get_parameter(Name=dbt.config.get('jdbc_url_path'), WithDecryption=True)['Parameter']['Value'] fetchsize = dbt.config.get('fetchsize') src = 'sample' print(f'table: {src}') data_q = f"(SELECT * FROM {src})" try: df = session.read.format('jdbc') \ .option('url', jdbc_url) \ .option('dbtable', data_q) \ .option('user', user) \ .option('password', pwd) \ .option('driver', 'oracle.jdbc.OracleDriver') \ .option('fetchsize', fetchsize) \ .load() except Exception as e: print(f"Error processing {src}: {e}") raise e return df
また、PL/SQLにも大きく2種類あり、バッチ処理として実行されているものと、レポーティングツールなどからテーブル関数のように利用され、最終的なSELECT 結果を取得するものがあります。前者は Oracle 上にテーブルとして永続化されていますが、後者は Oracle 上に結果が永続化されないため、そのままでは正解データを用意できません。そこで後者については、Databricks から PL/SQL を実行し、その実行結果を Databricks 上に永続化することで、正解データを準備できます。正解データの準備は、いずれの場合も dbt Python モデルを利用しています。
(例) PL/SQLのSELECT結果をDatabricksにロード
dbt Python モデルでは、jpype1==1.5.2 を利用して PL/SQL を実行し、実行結果を取得しました。
(当初は 「python-oracledb」 の利用を検討しましたが、一部のPL/SQLでライブラリのバグを踏んでしまい、タイムアウトする事象が発生しました。jpype1==1.5.3 は Issue があったため、安定して動作した 1.5.2 にバージョンを固定しています。PL/SQLが多いとバグを踏む機会も多くありました)
def execute_procedure(conn, spec: Dict[str, Any], fetch_full: bool = True, preview_rows: int = 10) -> Dict[str, Any]: proc_schema = spec.get('schema') proc_name = spec['name'] params_meta: List[Dict[str, Any]] = spec.get('parameters_full', []) call_sql = '{' + 'call ' + proc_schema + '.' + proc_name + '(' + ','.join(['?'] * len(params_meta)) + ')}' print(f"Executing: {call_sql}") # Force session date format to avoid ORA-01861 for procedures using TO_DATE without format mask try: fmt_stmt = conn.createStatement() fmt_stmt.execute("ALTER SESSION SET NLS_DATE_FORMAT='YYYY/MM/DD'") fmt_stmt.execute("ALTER SESSION SET NLS_TIMESTAMP_FORMAT='YYYY/MM/DD HH24:MI:SS'") fmt_stmt.execute("ALTER SESSION SET TIME_ZONE='Asia/Tokyo'") fmt_stmt.close() except Exception as e: print(f"[WARN] ALTER SESSION failed: {e}") stmt = conn.prepareCall(call_sql)
評価環境の準備
「コンバージョン評価プロセス全体の流れ」で紹介した通り、Procedureの「評価環境」を構築します。先ほどお伝えした通り、評価環境を構築するためにOracleの当日断面(インプットテーブル)と前日断面を利用します。構築時にはProcedureのデータ比較評価で得たフィードバックを前処理に反映しています。
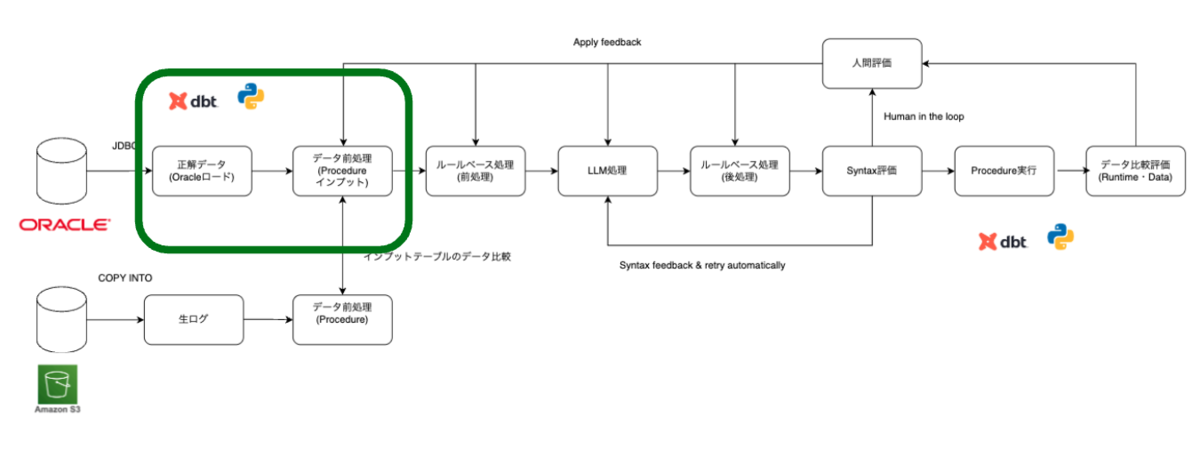
例えば CHAR 型の場合、Oracle では空文字が入った際に、定義された CHAR サイズ(例:CHAR(8))に応じてスペース埋めされた値が格納されます。一方、Databricks では CHAR サイズによるスペース埋めは行われません。そのため、テーブルを作成する際に、デフォルト値としてスペース埋めされるような対応を入れています。同様に、CHAR 型以外でも Oracle の DATE 型は「時刻」も持っているため、DatabricksではDATE型ではなく、TIMESTAMP型として扱う必要があります。このようにテーブル定義を作成する際にOracleとDatabricksのデータレベルの差分を前処理で吸収する必要があります。これらは最初からわかっていたわけではなく、Procedure のデータ比較評価結果を進める中で、継続的に改善していきました。
以下はDatabricks上でテーブル定義の情報を取得するクエリです。JDBCドライバで Oracle から Databricks にロードしたテーブルのスキーマ情報を管理する「information_schema」と、Oracle でスキーマ情報を管理している 「dba_tab_columns 」を利用して、今回のマイグレーションで利用している テーブル定義を作成しています。CHAR型かつデフォルト値がない場合、デフォルト値としてCHARサイズに応じたスペース埋めをデフォルト値として設定しています。
with information_schema as ( SELECT table_schema, table_name, column_name, data_type, full_data_type, ordinal_position FROM {copy_src_database_day_before}.information_schema.columns WHERE lower(table_schema) IN ('schema_a', 'schema_b') ), dba_tab_columns as ( select distinct OWNER, table_name, column_name, case when trim(DATA_DEFAULT) in ('NULL','null') then Null when trim(DATA_DEFAULT) in ('SYSDATE', 'sysdate', 'systimestamp', 'current_timestamp', 'SYSTIMESTAMP') then 'CURRENT_TIMESTAMP()' when trim(DATA_DEFAULT) == "'1980/01/01'" then 'to_timestamp("1980-01-01","yyyy-MM-dd")' else trim(DATA_DEFAULT) end as DATA_DEFAULT, NULLABLE from {database}.{schema}.dba_tab_columns where lower(OWNER) IN ('schema_a', 'schema_b') ) select a.table_schema, a.table_name, a.column_name, a.data_type, a.full_data_type, CASE WHEN lower(a.data_type) = 'char' AND b.NULLABLE = 'N' AND trim(b.DATA_DEFAULT) = "' '" THEN CONCAT("'", REPEAT(' ', CAST(REGEXP_EXTRACT(a.full_data_type, '(?i)CHAR\\\\((\\\\d+)\\\\)', 1) AS INT)), "'") ELSE b.DATA_DEFAULT END as DATA_DEFAULT, b.NULLABLE from information_schema as a left outer join dba_tab_columns as b on lower(a.table_schema) = lower(b.OWNER) and lower(a.table_name) = lower(b.table_name) and lower(a.column_name) = lower(b.column_name) ORDER BY table_schema, table_name, ordinal_position asc
作成したテーブル定義に対して、Procedure のデータ評価結果を考慮した前処理を行ったうえで、データを INSERT しています。CHAR 型のデータについては、値がオールスペースの場合はそのまま扱い、それ以外の場合は RTRIM を適用しています。これは、データ比較を進める中で、WHERE 条件や GROUP BY においてスペースの有無が差分として検知されるケースがあったためです。
また、文字列系はかなりややこしく、CHARやSTRING、VARCHAR型で挙動が異なります。当初は評価環境を構築する際に、ORACLEからロード済みのテーブルをSELECTする際に、適切なデータ型にCASTし、CREATE TABLEして構築していました。しかし、文字列系はCASTしてもCASTしたデータ型になりませんでした(CHAR(8)でCASTしてもSTRINGになってしまったり)。そのため、まず空のテーブルを作ってからINSERTするようにしました。これらもProcedure のデータ比較評価結果を進める中で、継続的に改善していきました。CHAR ではなく STRING になってしまうと、Procedure 内の WHERE 条件などでスペースを指定している場合、スペースの扱いが異なり、条件にマッチせず、適切な処理結果にならなくなります。
if 'char' in data_type: # If column contains only whitespace characters, keep original value; otherwise apply rtrim and cast to full_data_type column_selects.append(f"CAST(CASE WHEN `{column_name}` RLIKE '^\\\\s+$' THEN `{column_name}` ELSE rtrim(`{column_name}`) END AS {full_data_type}) as `{column_name}`") elif 'timestamp' in data_type: column_selects.append(f"CAST(CASE WHEN `{column_name}` IS NULL THEN NULL ELSE `{column_name}` - INTERVAL 9 HOURS END AS {full_data_type}) as `{column_name}`") else: column_selects.append(f"`{column_name}`")
「コンバージョン評価プロセス全体の流れ」で紹介した通り、インプットテーブルは当日断面、それ以外は前日断面から取得しています。
# copy_src_database:prod_oracle_20251225 # copy_src_database_day_before:prod_oracle_20251224 if is_source_table: insert_query = f"INSERT INTO {target_database}.{copy_src} SELECT {columns_str} FROM {copy_src_database}.{copy_src};" else: insert_query = f"INSERT INTO {target_database}.{copy_src} SELECT {columns_str} FROM {copy_src_database_day_before}.{copy_src};"
評価環境は評価者ごとにローカル環境から割り当てられた日付断面を使い、構築しています。dbtの設定ファイル(dbt_project.yaml)に変数として日付情報をセットすることで、対象日の評価環境を構築しています。
Databricks Procedureの実行
「コンバージョン評価プロセス全体の流れ」で紹介した通り、Databricks Procedureはdbt Python モデルから実行しています。Databricks Procedureは新しい機能なので、不安はあったのですか、もし何か問題があればPython で処理できるため、Databricks Procedureの導入を決める上で、安心材料となりました。
いきなり全 Procedure をテストすると原因調査が困難になるため、dbtのタグ機能を活用し、Procedure 単位で実行を制御しています。「dbt tag」を利用することで、実行時に 特定のタグだけ実行・除外 することができます。この機能を利用することで、同じdbtモデルファイルを利用し、Procedureの単体テスト、依存関係を考慮したProcedureの結合テストが可能となります。
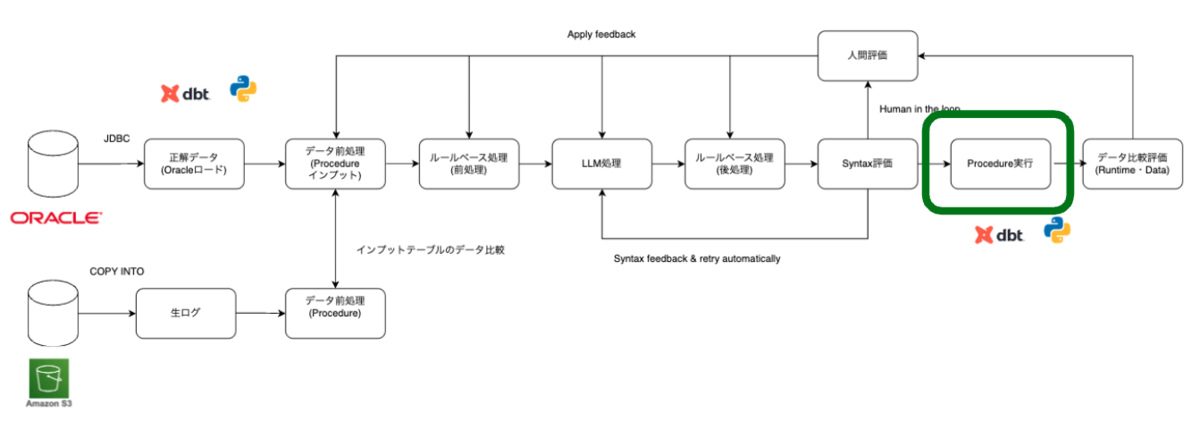
具体的には以下のような「dbt tag」を使っています。Procedrueの単体テスト、結合テストができるように「procedure名」、「procedureの属する親」、「procedureの属すスキーマ名」、「バッチ処理全体」単位と複数のタグを1つモデルに紐付け、依存関係も考慮した柔軟な実行単位の制御が可能です。
def model(dbt, session): dbt.config( tags=['<procedure_ parent_name>', '<procedure_name>', 'batch', '<procedure_schema>'] )
dbtのtagについて細かな挙動を確認してみた #dbt | DevelopersIO
また、「dbt.ref」を活用することで依存関係や同時実行数を考慮した並列実行が可能です。「dbt.ref」はdbtのSQLモデルとPythonモデル間でも定義することができます。マイグレーションをする場合、既存のPL/SQLの依存関係をそのまま持ってきたいことがあると思います。マイグレーションで依存関係を変更してしまうと、データ比較等で差分が出た場合、原因調査がむずかしくなるためです。Procedure間の依存関係は事前にメタ情報として定義し、メタ情報を利用して、dbt Pythonモデルファイルは自動生成しています。
def model(dbt, session): dbt.config( tags=['<procedure_ parent_name>', 'procedure_name', 'batch', '<procedure_schema>'] ) # Load reference models refs = [dbt.ref("procedure_a")]
About ref function | dbt Developer Hub
また、特定のカレンダー条件に応じて実行可否を制御したかったり、諸々の制約もあり、クラスターではなくSQL ウェアハウスのリソースを活用したいなどの特別な要件がある場合があります。そのような特殊な要件があっても、dbt Pythonモデルを使うことで柔軟に対応することができます。
通常の dbt は「1 モデル=1 テーブル」を前提としていますが、Procedureの場合、「1モデル= 1Procedure」となります。dbtの仕様上テーブル化しないといけないので(依存関係の制御でも利用)、Procedure 実行後に処理完了を示すタイムスタンプを返す運用をとっています。Procedureがどこまで完了してるか調べやすくしています。以下のような形をとっています。
from databricks import sql # Import databricks-sql-connector to use SQL Warehouse resources instead of a cluster. from utils import calendar import pandas as pd .... def model(dbt, session): # tag definition dbt.config( tags=['<procedure_ parent_name>', 'procedure_name', 'batch', '<procedure_schema>'] ) # model dependencies refs = [dbt.ref("procedure_a")] # Control execution eligibility based on specific calendar conditions. if calendar.should_execute_today(dbt.config.get("calendar_table"), "bizday", session, dbt.config.get("calendar_date")): print('sp execute') try: # Procedure execution procedure_b(spark=session, params=params) # Return the procedure completion timestamp. return session.sql("SELECT current_timestamp() as createdtime, 'success' as status") except Exception as e: error_msg = f"Model procedure_b execution failed: {str(e)}" print(f"ERROR: {error_msg}") raise e # Return the procedure completion timestamp. return session.sql("SELECT current_timestamp() as createdtime, 'skip' as status")
データ比較評価
「コンバージョン評価プロセス全体の流れ」で紹介した通り、Procedureの実行結果をOracleの正解データと比較して評価します。また、Procedureの評価完了後はProcedureのフィードバックを反映した「評価環境」を正解データとし、インプットテーブルの評価も必要です。
Procedure単位での単体テストを行うため、事前にメタ情報としてProcedure単位で、書き込み処理をしてるテーブル一覧を整理しています。Procedure の実行によって更新されるテーブルを対象にデータ比較評価することで、Procedure 単体でのテストが可能になります。
write_tables: - table_name: table_a procedure: procedure_a schema: schema_a - table_name: table_b procedure: procedure_a schema: schema_a - table_name: table_a procedure: procedure_b schema: schema_b
Databricks Procedure の実行結果を評価するために、dbt Audit Helper を活用しています。カラムレベルおよびレコードレベルでのデータ比較が可能で、一致率も算出できるため、これらを指標として差分検知を行っています。dbtのエコシステムを使えるので、自前で作る必要もなく便利でした。
以下は行レベルの比較処理を行うサンプルとなります。「summarize」オプションを「TRUE」にするとデータ比較の一致率を確認することができます。「FALSE」にすると具体的にどの行で差分が発生しているかわかります。カラムレベルの比較等も可能です。データ比較結果はdbtモデルとしてテーブルに書き込まれます。
github.com
「dbt tag」は Procedure の実行単位に合わせて設計しています。これにより、Procedure 実行後に更新されたテーブルに対してデータ比較テストを実行できるようになっています。これらのファイルについても、先ほど紹介したメタ情報を利用して自動生成しています。
{{ config(
materialized='table',
tags=['<procedure_schema>', '<procedure_name>_test', '<procedure_parent_name>_test', '<table_name>_compare_queries_summarize', 'test_compare_queries_summarize']
) }}
{% set old_query %}
select
col_1,
col_2
from {{ var('catalog_table_compare_old') }}.<schema_name>.<table_name>
{% endset %}
{% set new_query %}
select
col_1,
col_2
from {{ var('catalog_table_compare_new') }}.<schema_name>.<table_name>
{% endset %}
{{ audit_helper.compare_queries(
a_query = old_query,
b_query = new_query,
summarize = true
) }}
以下のようにして、「dbt tag」で単体テストをしたいProcedureのデータ比較が可能です。データの比較結果はテーブルとして書き込まれます。
pipenv run dbt run --target=prod --select tag:<procedure_name>_test --threads 5
dbt Audit Helperのデータ比較結果に対して、dbt test を実行し、データ比較結果(一致率)に差分があった場合は検知できるようにしています。検知された結果は「人間」が確認し、LLM コンバージョンツールや評価環境構築処理、メタ情報などにフィードバックすることで、データレベルでの改善サイクルを回しています。dbt testファイルは以下のようにしています。
{{ config(
tags=['batch', '<schema>', 'test_<table_name>', '<procedure_name>_test', '<procedure_parent_name>_test']
) }}
select
1
from
{{ var('catalog_compare_new') }}.{{ var('schema_dbt_model') }}.<table_name>_<schema_name>_compare_queries_summarize
where
not (in_a = 'true' and in_b = 'true' and percent_of_total = 100)
以下のコマンドでテストできます。単体テスト、結合テスト等テストフェーズに合わせた「dbt tag」を指定し、柔軟にテストすることができます。
pipenv run dbt test --target=prod --select tag:<procedure_name>_test --threads 5
データ比較評価結果のフィードバック
「コンバージョン評価プロセス全体の流れ」で紹介した通り、データ比較評価結果のフィードバックはLLMのコンバージョンツールだけではなく、データの前処理、メタ情報、Oracle互換のUDF等多岐に渡ります。差分を確認した場合、どこに、どのように反映していくのが適切か人間が判断していく必要があります。運用としては、評価者が データ比較後に原因を調べ、Databricks Procedure を修正した Pull Request を作成し、レビュー担当者がその差分を確認したうえで、適切なフィードバック先を評価者と議論し、判断する運用としました。フィードバックに必要なコンテキスト情報は、基本的にはPull Request から取得する運用としています。
大変だったこと
プロンプトチューニングに伴うLLMのデグレ対応
データ評価のフィードバックをプロンプトへ反映していく過程で、コンテキストが肥大化し、精度がデグレする現象を確認しました。デグレが発生した場合は、GitHub 上でバージョンを戻すなどの対応を行いました。
また、以下のような運用と対策を取りました。
- ルール処理で対応可能なものは、極力ルールベースで処理する(コンテキストの肥大化を防ぐ)
- 変換結果は Pull Request でレビューする運用とする(GitHubの差分で明らかなデグレが発生していないか確認する)
- 評価済みの Procedure は再コンバート対象から除外する
- 変換処理を「LLM 処理」か「ルール処理」のいずれかに明示する(曖昧だとLLMの知識に頼ることになり、変換結果が不安定になる)
- 行数が多く、ビジネスロジックを含まないバッチ系 Procedure から優先的にコンバージョンを進める(ビジネスロジックは行数が少ないものの複雑な処理が増え、プロンプトのコンテキストが増えるため)
ルールベース処理と異なり、LLM は非決定的であるため不安定な側面があり、プロンプトのチューニングは手探りで進める必要がありました。そのため、プロンプト調整やデグレ対策には特に難しさを感じました。
データ比較評価
Syntaxレベルのテストは全Procedure1週間程度でクリアできましたが、データ比較はかなり大変でした。本記事でも一部ご紹介しましたが、データ比較で差分が出た場合、原因は多岐に渡ります。また、Procedureをテストするためのデータ準備等も自動化しているとはいえ、待ち時間はかかります。特に、複数の Procedure が同一のテーブルを更新している場合、原因調査はさらに難しくなります。正解データとして参照できるのは Oracle のバッチ完了後の断面のみであり、複数の Procedure によって更新された「最終更新結果」としかデータ比較ができないためです。その結果、どの Procedure の処理で問題が発生したのかを特定するのは困難になります。また、Procedureが更新するテーブルを評価することで、Procedureと関連のあるテーブル定義、UDF、前処理済みデータ、メタ情報、Procedure自体、どこに問題があっても検知はできますが、原因調査は大変です。できるだけシンプルにできるよう、Procedrue全体ではなく、単体で評価できる仕組みを作ったり、依存関係は既存のOracleの依存関係をそのまま利用するようにしました。
パフォーマンス改善
ご紹介したとおり、LLM コンバージョンツールを用いて Oracle の PL/SQL を Databricks Procedure にコンバージョンしました。しかし、OLTP を前提として作られている Oracle の PL/SQL を OLAP の Databricks に移行するにあたり、パフォーマンス面が大きな課題となりました。詳細については、以下の記事内の「Databricks Procedure導入課題」をご確認ください。
case-k.hatenablog.com
学び
コンバージョンプロセス全体を管理し、改善サイクルを高速に回す重要性
コンバージョンプロセス全体を管理し、評価結果を適切なプロセスへフィードバックしながら、継続的に改善していく仕組みの重要性を改めて感じました。コンバージョン評価結果を「人間」が確認後、フィードバック先は多岐に渡るので、全体のプロセスを管理し、改善サイクルを高速に回すことが大切です。全体ではなく、一部のプロセスにしかフィードバックできないと厳しかったです。LLM と dbt の各種機能を活用することで、PL/SQL のコンバージョンからデータ評価までを自動化でき、改善サイクルを高速に回せるようになりました。また、Databricks Procedure がサポートされたことで、SQL ウェアハウスから直接実行できるようになった点も、改善サイクルの高速化に寄与しています。さらに、PL/SQL のコンバージョンからデータ比較評価までをローカル環境で実行、検証できる仕組みを整えたことも、改善サイクルを迅速に回すうえで大きく寄与したと感じています。
LLMの力とソフトウェアエンジニアリングの重要性
LLM の登場により、これまでは諦めていたようなマイグレーションも、現実的な工数でできる時代になったと感じます(大変なことには変わりありませんが)。フィードバックを反映していくことで、マニュアル修正なしでデータ比較テストをパスするものが増え、コンバージョンペースは加速的に上がっていきました。ただし、LLM はそのまま使うだけでは十分な精度を発揮できず、現時点ではコンテキストエンジニアリングといった、ソフトウェアエンジニアリングが不可欠であることも実感しました。LLM をマイグレーションプロセスに組み込み、工数削減につながるレベルの成果を出すためには、十分に高い精度が求められます(特にデータ比較において差分が発生すると、その原因調査が必要となり、全体の進行ペースが大きく低下しました)。全体設計からコンテキストエンジニアリング、評価基盤、フィードバック改善プロセスの運用設計などソフトウェアエンジニアとしての能力が重要に思いました。
OSSへのコントリビュート機会
今回のマイグレーションを通じて、OSS にコントリビューションする機会がありました。dbt Python モデルの検証を進める中で、Job のアクセスコントロールに問題があることが分かりました。また、Notebook と Job の権限を分けて制御できなかったので、両者を分離できるよう機能追加および修正を行いました。
github.com
また、Databricks のコンソールから実行中のジョブをキャンセルした場合でも、成功として扱われてしまう問題もありました。これに対しても修正のための Pull Request を作成し、マージしてもらいました。
github.com
マージされるまではdbt Pythonモデル内でAPIを使い、パッチ対応しました。Databricksは他のOSSも含めてレビュー速度が非常に速いと感じます。組織としてOSSに注力されているのを感じます。また、機会等あればコントリビュートしていきたいです。
エージェントを活用したデータ比較評価の更なる自動化
ご紹介したとおり、Procedure の単体テストは、「人間」がローカル環境から各 dbt コマンドを実行して行ってきました。評価担当者は、データ比較で差分が検知された場合に原因を調査し、修正内容を反映した Pull Request を作成します。レビュー担当者がその Pull Request の内容を確認し、前述のとおり適切なコンバージョンプロセスへフィードバックします。
しかし、Claude Codeなどをデータ比較評価エージェントとして活用すれば、データ比較評価でもさらに自動化できた可能性があります。dbt評価基盤や各APIを「ツール」として扱い、dbt コマンドの実行から、データ比較評価、テーブルやファイルアクセスの伴う差分の原因調査、原因調査後の修正と再評価、修正結果を反映したPull Request の作成まで実現できるように思います。各コマンドはローカル環境から実行可能であり、差分発生時の原因調査方法も「人間」がエージェントのプロンプトにフィードバックできます。今回は制約もありそこまで踏み込めなかったのですが、PL/SQLのコンバージョンだけではなく、データ比較評価でも、エージェントを活用することで、データ比較評価を更に自動化できたように思います。
まとめ
LLMコンバージョンツール(LLM処理・ルール処理)と dbt 評価基盤の紹介をしました。LLMが使えなかったらコンバージョンは難しかったです。ただし、LLM はそのまま使うだけでは十分な精度を発揮できず、履歴管理やルール処理を含めた コンテキストエンジニアリング といった、ソフトウェアエンジニアリングが不可欠であることも実感しました。また、コンバージョン結果を評価するために評価基盤の整備が必要です。dbt を活用することで、依存関係の制御、タグを用いた単体テストから結合テストまで実行単位の切り替え、特定の日付断面を用いたローカル環境からの実行、テーブル定義や評価用データの準備、dbt Audit Helperを用いたデータ比較も同一のインターフェース上で実現できました。最後に、今回のコンバージョンを通じて、コンバージョンプロセス全体を管理し、評価結果を適切なプロセスへフィードバックしながら、継続的に改善していく仕組みが非常に大切だと思いました。LLM時代に評価基盤はセットですね。最後まで読んで頂きありがとうございました。良いお年を。